Lektion 9: Suchmaschinen und Discovery-Systeme
Nachtrag zu Suchmaschinen und Discovery Systeme
Folio
Als Konkurrenz zu Alma wurde ein open source, cloudfähiges Bibliothekssystem entwickelt namens Folio. Folio wird in der Zukunft voraussichtlich an Bedeutung gewinnen. Es wird von EBSCO finanziert mit dem starken Fokus auf open source. Weil der Trend in der Bibliothekswelt immer mehr Richtung open source geht, finde ich dies eine sehr passende Entwicklung und werde sie mit Spannung verfolgen. Es ist toll, dass Folio auch auf die einzelnen Institutionen personalisiert werden kann und die Dienste über Applikationen erweitert werden können.
Praxisberichte
Entwicklung eines neuen Online-Katalogs für das Deutsche Literaturarchivs Marbach
Das Deutsche Literaturarchiv in Marbach ist gleichzeitig ein Archiv, eine Bibliothek und ein Museum. Deshalb sind die Bestände in dieser Institution sehr unterschiedlich und die Daten nicht homogen. Für jeden Teilbereich gibt es eine eigene Suche, was für die Nutzer relativ mühsam ist. Das Ziel des Projektes war es deshalb, die Daten von allen drei Teilbestände in eine Suche zu vereinen.
Das Projekt wurde in die folgenden drei Schritte gegliedert:
- Prototyp erstellen: Datenanalyse (wie homogenisieren?), Vorschlag präsentieren
- Projektstart mit einem Experten für Bibliothekssysteme und einem Experten von Vufind
- Software typo3 verwendet, Datenintegration
Das Literaturarchiv hat eine sehr gute Datenqualität. Dies liegt daran, dass sie in allen drei Teilbereichen sehr früh angefangen haben mit Normdaten zu arbeiten.
Weil ich selber die Ausbildung im Sozialarchiv in Zürich gemacht habe, interessiert mich dieses Projekt sehr. Das Sozialarchiv besteht nämlich aus vier Teilbereichen, dem Archiv, der Bibliothek, der Sachdokumentation und dem Bild-und-Ton-Archiv. Für all diese Teilbereiche haben sie verschiedene Datenbanken, was für die KundInnen sehr mühsam und unübersichtlich ist. Da sie aber nur im Bibliotheksbereich mit Normdaten arbeiten, ist die Datenqualität wahrscheinlich nicht so hoch wie beim Literaturarchiv in Marbach. Trotzdem wäre eine Suche die über alle Teilbereiche geht, sehr wertvoll.
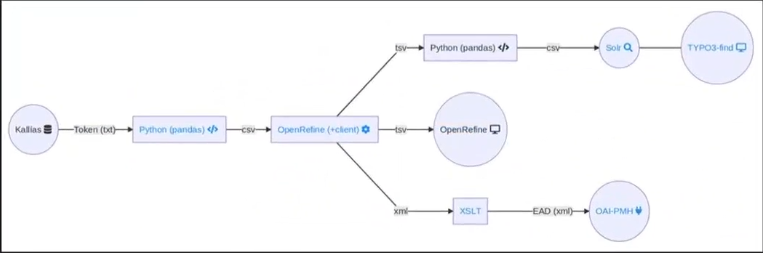
Aus der Kalias Software wurden die verschiedenen Daten exportiert. Mit der Software Pandas wurden dann die Daten geladen und einfache Fehlerbereinigungen durchgeführt und die Daten dann ins CSV-Format konvertiert. In OpenRefine wurden die Daten dann homogenisiert und vereinheitlicht und schliesslich ins Format tsv umgewandelt. Mit Pandas mussten dann die Daten nochmals angepasst werden um sie schliesslich in Solr einzuspielen. Von dort wurden die Daten dann ins Typo3 und OpenRefine geladen. Zudem können die Archivdaten über die OAI-Schnittstelle geladen werden.
Datenintegration für das Portal naah.nrw
Für das Portal noah.nrw wurden Datenintegrationen durchgeführt. Dabei werden die Daten über eine OAI-Schnittstelle geladen, ins Format METS/MODS konvertiert und dann über eine OAI-Schnittstelle bereitgestellt. Es wurde unter anderem mit der Software visual library gearbeitet.
Linked Data
Bibframe
Bibframe wird in der Zukunft höchstwahrscheinlich Marc21 ablösen. Anders als Marc21 basiert es auf Linked data und nutzt FRBR für die Strukturierung der Daten. Bei Bibframe können archivische und bilbiothekarische Daten ähnlich beschrieben werden und daher besser untereinander ausgetauscht werden. Bei Linked Data geht es nicht mehr darum, alle Informationen in einen Datensatz zu packen. Die Teile werden einzeln beschrieben und dann miteinander in Relation gesetzt. Zum Beispiel soll der Name vom Autor nicht mehr im Datensatz vom Werk abgelegt werden, sondern in einem separaten Datensatz - diese werden dann miteinander verknüpft. Es wird ein Gesamtdatenpool angestrebt.
Records in Context (Ric)
Ric ist ein neuer Standard für Archivsysteme, sowie Bibframe für die Bibliothekssysteme. Der Nachteil vom älteren Standard ISAD(G), ist dass keine Relationen zwischen Entitäten möglich sind. Bei Ric ist dies durch open data möglich. bei Ric ist dies durch open data möglich In Archiven wurde bisher nicht wirklich mit Normdaten gearbeitet. Durch diesen linked data Ansatz gibt es jetzt eine starke Veränderung der Datenstruktur. Mit dem Wechsel auf Ric und dem Linked Data Prinzip, kommt viel Arbeit auf die Archive zu. Viele Formate müssen konvertiert werden.
4654 Zeichen