Lektion 8: Suchmaschinen und Discovery-Systeme
Warum lernen wir über Metadatentransformation?
In der Praxis gibt es Teams in fast jeder grösseren Bibliotheken die sich Vollzeit mit Metadaten-Management beschäftigen. Wie zum Beispiel Frau Jeude aus der ZBW in Leibzig. Sie führt Datensätze aus verschiedenen Quellen in eine Datenbank zusammen und muss dafür die verschiedenen Metdatenstandards umwandeln. Der Zweck davon ist, dass die Nutzer in einer Datenbank, Datensätze aus verschiedenen Quellen finden.
Alternativen zu OpenRefine:
In der letzten Vorlesung sind wir bereits auf die Merkmale von Openrefine eingegangen. Heute wurden die Alternativen von OpenRefine angesprochen. Catmandu wurde im Rahmen einer freien Repository Software entwickelt und hat den Zweck Daten zu transformieren. Die Software verfügt über umfangreiche Funktionen und unterstützt viele Datenformate und Schnittstellen. Der Vorteil bei der Nutzung von Metafacture ist, dass die Software in Java geschrieben ist und als Bestandteil eigener Programme implementiert werden kann. Mit Metafacture sind auch sehr komplexe Transformationen machbar. Ausserdem liegt der Fokus vor allem auf der Transformation von Marc21 Dateien. Es gibt noch viele weitere Alternativen wie zum Beispel MarcXimil oder d:swarm. In dieser Vielfalt an Software ist es nicht ganz einfach, die passende zu finden. Je nach Systemvoraussetzungen , Verwendungszweck und Vorkenntnisse muss eine Entscheidung gefällt werden. Die Programme auch kombiniert werden.
Solr vs. Datenbank
Solr ist open source und kann gut mit grossen Datenmengen umgehen. Solr wurde vor allem für den Abruf und das Wiederfinden von Datensätzen konzipiert während Datenbanken vor allem auf die Datenspeicherung und Erhaltung der Daten fokussieren. Mit Solr kann man sehr grosse Datenmengen, sehr schnell durchsuchen. Um dies zu ermöglichen, verfügt Solr über eine sehr flache Datenstruktur. Die Daten werden einfach als Listen mit Feldern und Werten angezeigt. Solr ist vor allem für statische Daten geeignet, die sich nicht oft ändern. Bei einer Datenbank hingegen, sollen die Daten effizient gespeichert werden. Dabei soll möglichst wenig Speicherplatz gebraucht und Redundanz vermieden werden. Dafür werden mehrere Tabellen erstellt und die Tabellen mit Relationen verbunden. Datenbanken eignen sich auch für veränderliche Daten.
Unterschiede zwischen Vufind und Solr
Da ich den Unterschied noch nicht ganz verstanden habe, habe ich hier nachgelesen: http://3.250.15.189/solr.html Das Discovery System Vufind basiert auf Solr. Solr kann als Motor der Suchfunktion bezeichnet werden, der sicherstellt das Vufind funktioniert. Vufind bietet eine grafische Suchoberfläche und Einstellungen, sodass die Nutzer nicht direkt mit Solr arbeiten müssen. Im Solr wird ein umfangreicherer Datensatz angezeigt als bei Vufind und die Querytime von Solr ist schneller
Gruppenübung zur Datenintegration
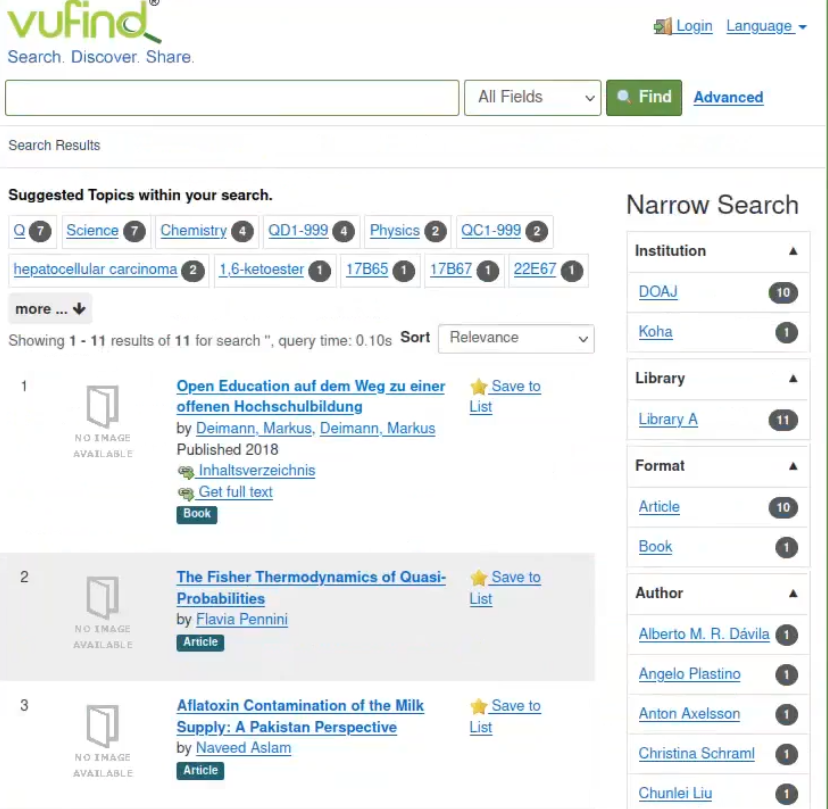
In unserer Gruppe hat es problemlos geklappt. Wir konnten alle Schritte ausführen, sodass am Schluss 11 Resultate angezeigt wurden.
Grafik
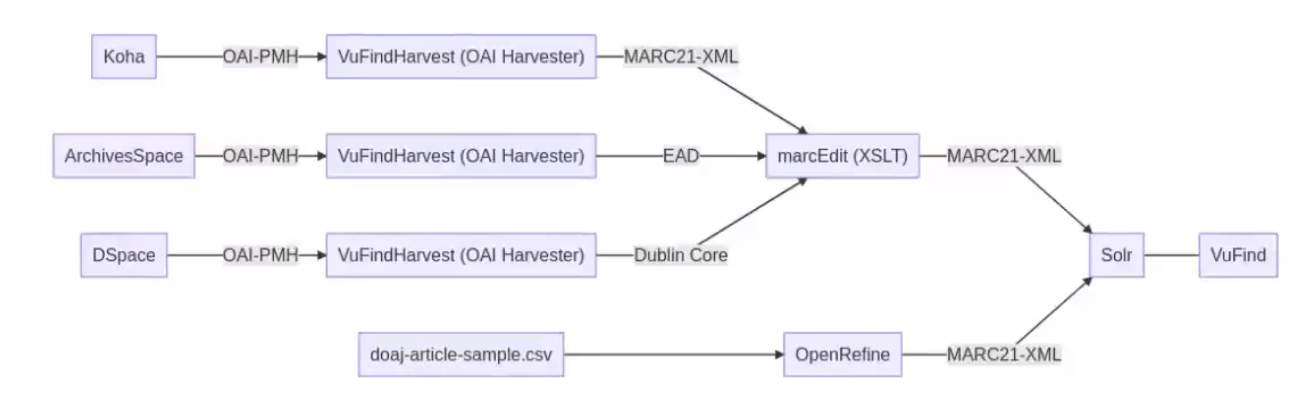
Im Laufe des Kurses hatten wir Koha, Archivesspace und DSpace installiert. Bei all diesen Programmen hatten wir jeweils Inhalte erstellt. Bei Koha hatten wir ein Medium und einen Nutzer erstellt, bei Archivesspace eine Accession, eine Ressource und ein archival objekt. Bei Dspace haben wir ein eine Collection/Community angelegt und ein Dokument angehängt. Über die Schnittstelle OAI-PMH und dem Programm Vufind harvest haben wir die erstellten Daten aus Koha und Archivesspace geharvestet oder anders gesagt heruntergeladen. Die Daten von Dspace haben wir direkt über die OAI-PMH Schnittstelle aus der Website geladen. Für die Weiternutzung dieser Daten mussten wir sie noch in den Metadatenstandard “Marc21-XML” umwandeln. Dazu haben wir das Programm marcEdit (XSLT) verwendet. Des weiteren haben wir den Doaj Beispieldatensatz im Tabellenformat über den Exporter von OpenRefine in Marcxml in den Suchindex Solr geladen. Vufind verwendet die Software names Solr.
Zeichen:3988