Lektion 6: Metaddaten modellieren und Schnittstellen nutzen 1/2
Discovery system vs OPAC
Der OPAC ist der klassische Online Katalog einer Bibliothek aber für die heutigen Recherchebedürfnisse der Nutzer ist er ziemlich veraltet. Das Discovery System orientiert sich stark am Design von Google und die Suche besteht aus nur einem Suchschlitz. In meiner Lehrzeit hatte ich noch mit einem älteren OPAC Katalog gearbeitet, man konnte damit sehr spezifische Abfragen machen, die man bei vielen Discovery-Systemen nicht kann. Allerdings ist die Suche auch viel komplexer im OPAC. Ich finde das Design vom Discovery System «swisscovery» sehr schön, allerdings vermisse ich die Möglichkeit, nach Strichcodes von Büchern zu suchen.
Austauschprotokolle / Übertragungsprotokolle
OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting) habe ich zwar auch schon in den Vorlesungen gehört aber ich kann mir noch nicht wirklich viel darunter vorstellen. Es dient dem Sammeln/harvesten von Metadaten, die auf sogenannten Data Providern bereitgestellt werden. Es wird vor allem für den Gesamtabzug oder für die Kopie von Daten verwendet. Damit werden wir heute unsere Daten von Dspace, Archivesspace und Koha «harvesten».
Wir haben noch zwei andere Übertragungsprotokolle angeschaut. SRU ermöglicht die dezidierte Recherche, ohne eine eigene Datenbank vorzuhalten. Diese Schnittstelle ist ohne Zusatz im Browser nutzbar und eignet sich vor allem für den Live Datenabzug. Der KVK Katalog und der Katalog der deutschen Nationalbibliothek (DNB) funktionieren mit einer SRU-Schnittstelle.
Das Z39.50-Protokoll wurde ursprünglich von der library of congress entwickelt und ist heute ziemlich veraltet. Es wird dafür eine Spezialsoftware benötigt während die SRU einfach im Browser angezeigt wird.
Übung Harvesting
Um die Daten über die OAI-PMH Schnittstelle zu «harvesten» mussten wir das Programm VufindHarvest mit dem Terminal installieren. Dies hatte gut geklappt.
Um die Daten herunterzuladen musste das Programm zur gleichen Zeit am laufen sein. Es hatte bei mir wieder mal ziemlich lange gedauert, bis Archivesspace geladen hatte. Weil das Terminal nach dem öffnen von Archivesspace sehr beschäftigt war, habe ich ein zweites Terminal Fenster aufgemacht für den Befehl des Abzuges. Dies hatte dann nach einigen Fehlversuchen geklappt und ich konnte die Datei als EAD abspeichern.
Als ich dann noch Koha harvesten wollte, konnte ich leider die Seite von Koha nicht mehr richtig aufrufen. Es kam die Fehlermeldung 404. Ich hatte es dann trotzdem noch im Terminal probiert aber auch da kam die Meldung das kein Dokument gefunden werden konnte, weil die Seite unterreichbar ist. Ich habe später bemerkt, dass es sein kann weil ich die OAI-PMH Schnittstelle in Koha nie aktiviert hatte. Ich habe es also nochmals versucht aber leider gab es jetzt eine neue Fehlermeldung im Terminal:

XSLT Crosswalks (Crosswalk: Prozess der Konvertierung von einem Metadatenstandard in den anderen)
Wir haben das Programm Marcedit (XSLT) verwendet, um die Daten zu konvertieren.
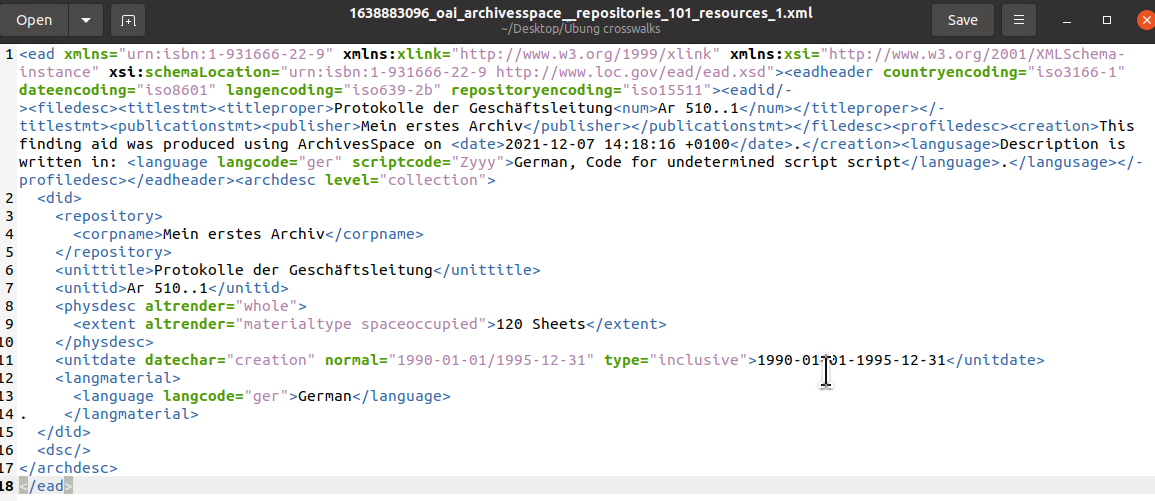
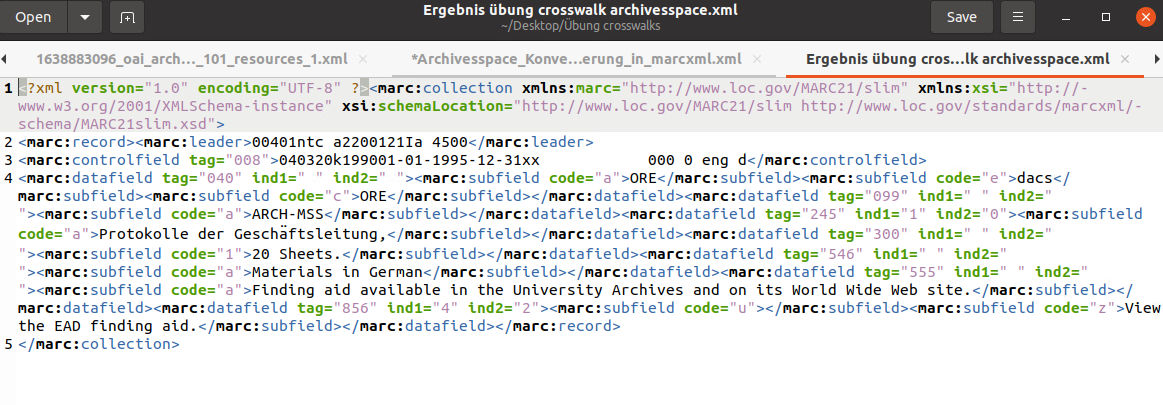
Der Transfer von Archivesspace EAD zu XML hatte problemlos geklappt:
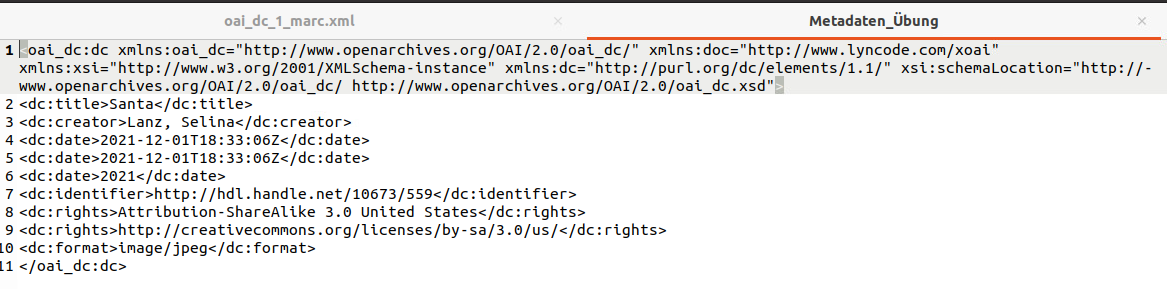
Die Metadaten aus Dspace hatten wir ja als Hausaufgabe manuell aus der Schnittstelle geladen. Diese Daten sehen bei mir so aus:
Die Konvertierung der Daten aus Dspace (OAIDDC) nach XML hat ohne Probleme funktioniert:
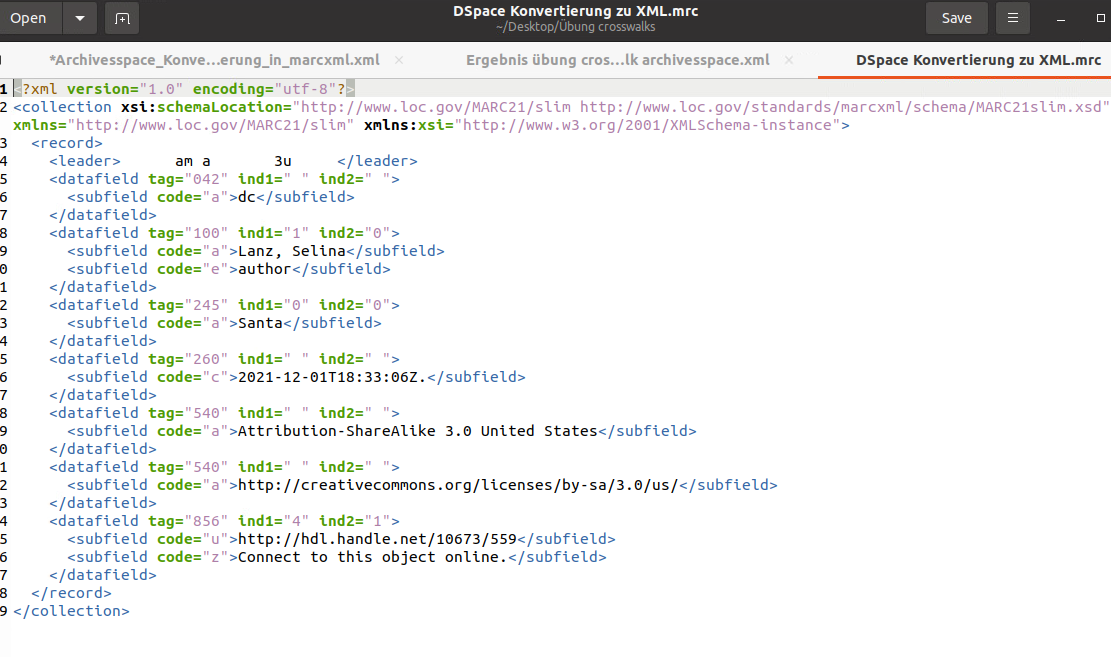
Diese Übung fand ich ganz schön herausfordernd. Als ich schliesslich das Resultat erhalten hatte, war ich aber schon ein wenig stolz.